
Today's fast-paced digital landscape demands software delivery that's quick and efficient. Our approach to deployments is to leverage container-based deployments using Kubernetes to enable rapid deployments, reduce costs, and enhance transparency – all without sacrificing reliability and stability.
While many organizations claim to practice CI/CD (continuous integration/continuous delivery), what they often mean is simply having any deployment pipeline. True continuous integration/delivery means that every new change is tested and deployed immediately, enabling rapid turnaround on new features and bug fixes. However, this is only realistic with a strong commitment to automated testing.
The goals
Rapid deployments: We prioritize deployment speed and developer efficiency in our approach. By simplifying and automating as much of the process as possible, we minimize manual intervention and the time it takes to ship new features and fixes.
Transparency: We aim to empower the team to test and share updates without the fear of taking down a critical environment. This also lets key stakeholders get early previews of new features and fixes before they make their way to production.
Cost efficiency: Our strategy focuses on keeping costs low by leveraging reusable components and eliminating unnecessary long-running deployments, which can be especially important for smaller organizations.
Reusability: We design our pipelines to be adaptable and reusable across projects. This means that spinning up a new project with a robust testing and deployment process is quick and effortless. Learn more about our reusability philosophy in our [StarterKits guide](link-to-starterkits).
Cross-platform compatibility: Our container-based setup is agnostic to the container orchestration tool, making it easy to deploy a wide range of products and APIs without vendor lock-in. It's easy to migrate to another cloud service provider as long as they support Kubernetes, or another container-based deploy service such as Snowflake's Snowpark Container Services or AWS ECS.
How it works
TL;DR:
In short, our development process is outlined in the following diagram. Below, we break down the strategy into several sections detailing each step of the workflow.
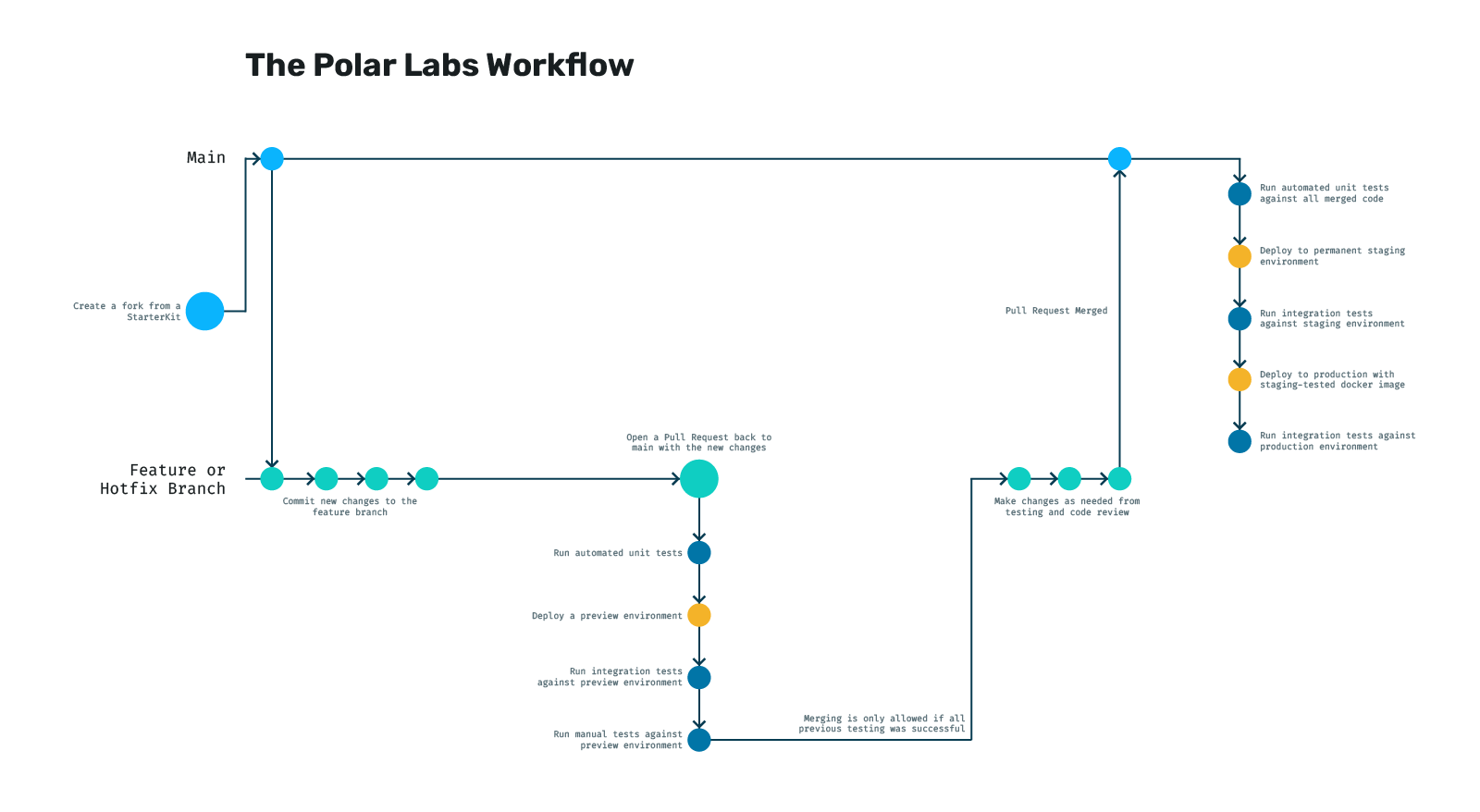
Our preferred git strategy
Unlike the popular "Gitflow model”, which can lead to convoluted release processes, we keep our own workflow simple following the “GitHub model”. In short, we maintain a single “main” branch and if new code isn't good enough for production, it's not good enough for the main branch. When new code merges into main, it's deployed immediately to a staging environment for testing, then right to production, where it's tested one final time.
Gitflow Model
The standard Gitflow model looks something like the diagram below. You have a main branch and a develop branch as your primary branches. All new features are branched off of the develop branch and, when they are complete, they're merged back to develop. When it's time for a new release/deployment, a branch is made off of develop with the current state of develop and usually deployed to a staging environment of some kind. If everything looks good, the branch is merged to main and deployed to production, then back to develop. The release on main is then tagged with the version. If a bug needs to be fixed in production, you branch off main and fix it before merging back to both main and develop.
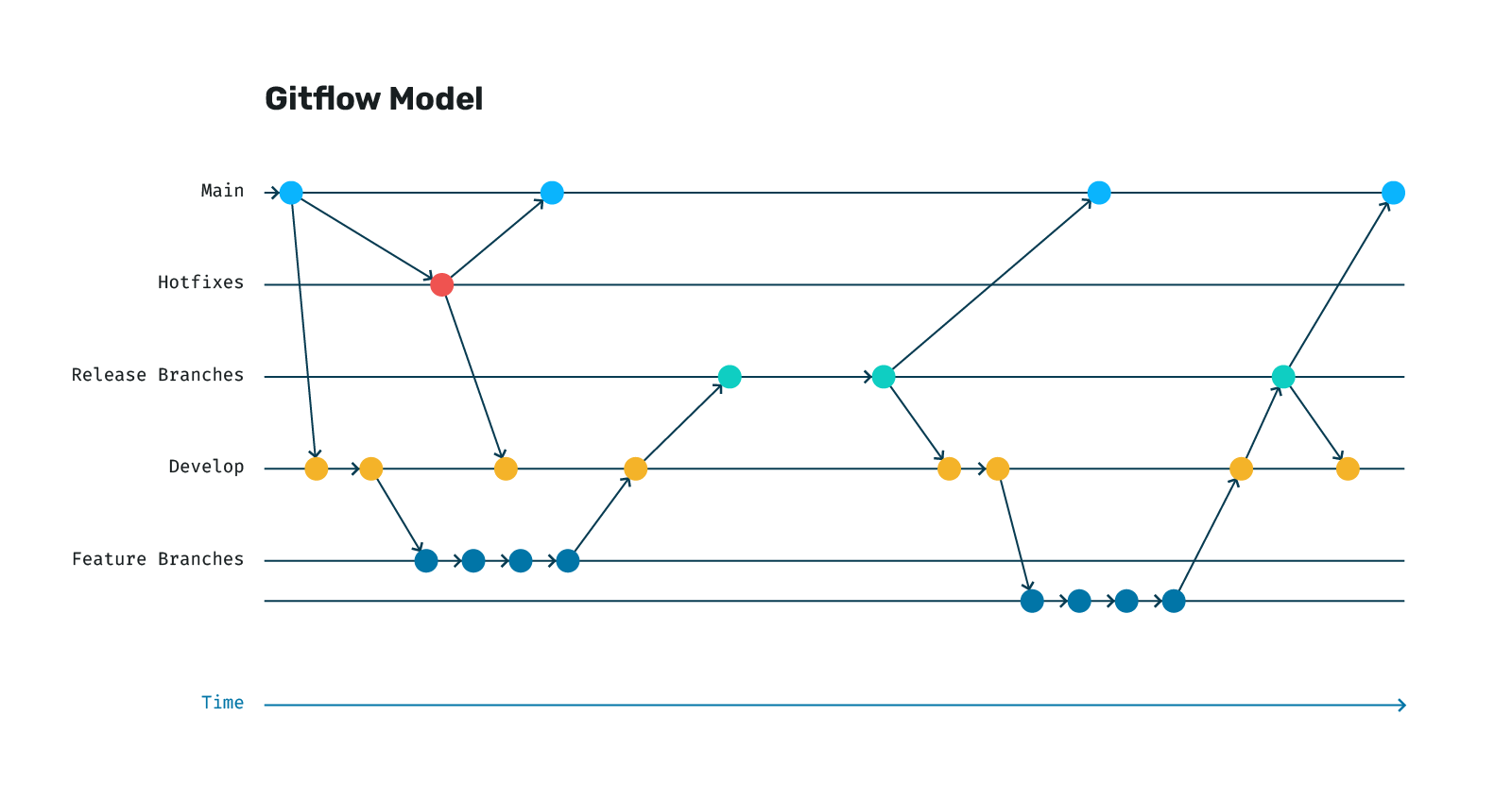
There is another variation of this model where you have a permanent staging branch instead of ephemeral release branches. This is often done when organizations want to couple branches to specific environments for continuous deployment. The flow is ultimately the same, but you merge develop to the permanent staging branch instead of a new release branch.
If you are finding it a bit complicated and difficult to follow, you're not alone. This model can work well for larger organizations that want more control over their releases and to bundle together many changes into single releases, but it can be difficult to acheive true continuous integration and deployment as new releases are large with many changes and must go through many steps to get into production.
GitHub Model
In the GitHub model, things are greatly simplified as you can see in the diagram below. The idea is twofold:
- All code you write should be production-ready and backwards compatible by default.
- Automated testing must be a top priority to enable a faster, simpler flow that doesn't sacrifice stability.
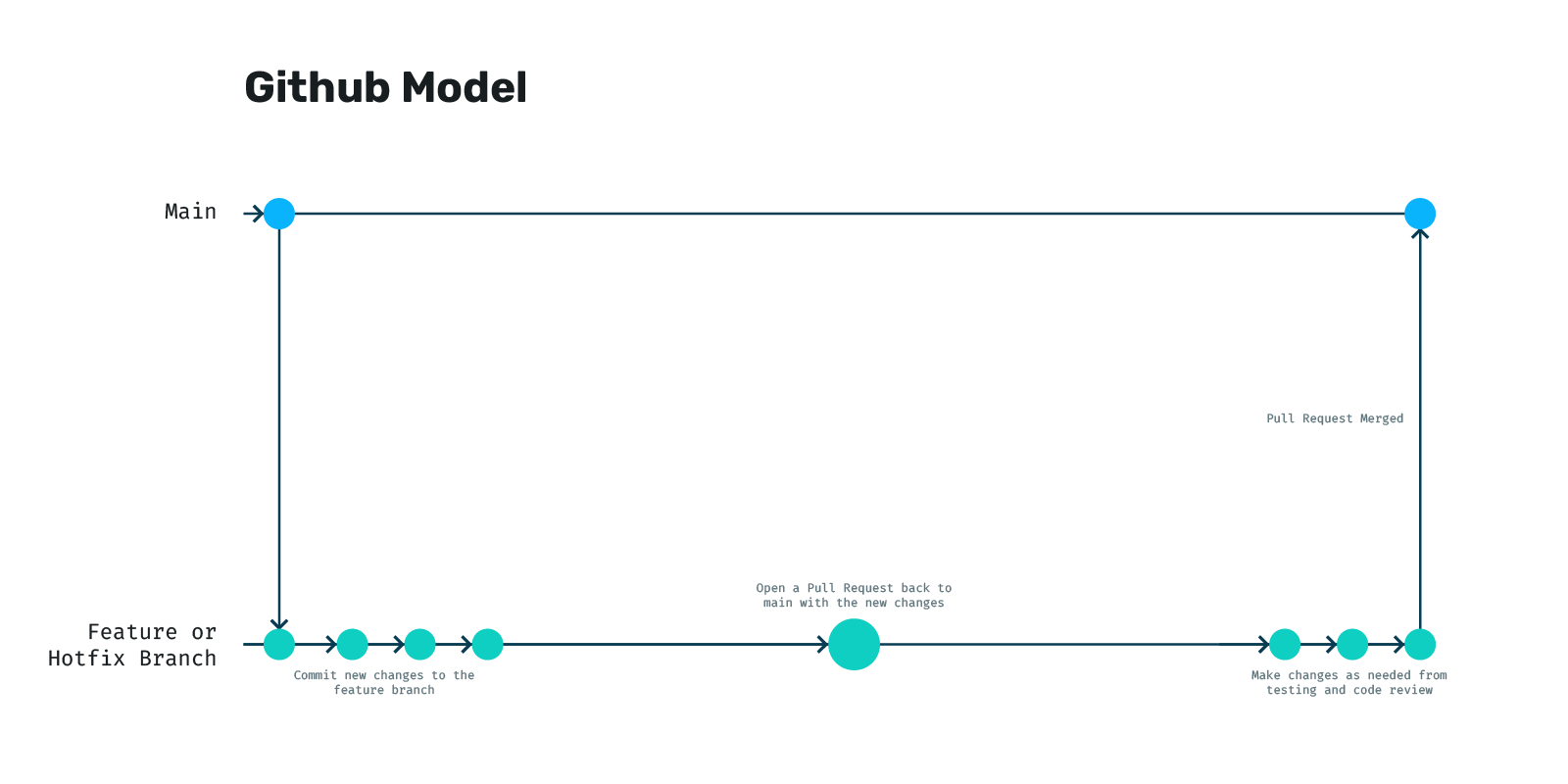
In this model, all new features branch off main and return from whence they came. Before they are merged, a pull request is opened with the changes and an extensive code review is performed (ideally) to make sure the new changes look good.
Now, if you're looking at this model and thinking to yourself, “this looks real easy to ship a bug”, you are once again not alone! We completely agree and account for this in the way we extend this model in the next sections.
How we deploy the containers
To manage our containerized applications, we prefer managed Kubernetes clusters, however other container orchestration tools, such as Snowpark Container Services on Snowflake or ECS (Elastic Container Service) on AWS, could be substituted easily. The key idea is that all applications are self container in a Docker image and can be deployed anywhere. A container-based approach gives us the flexibility to remain cloud agnostic and scale our infrastructure resources up or down as needed; simply add more containers to scale out. Using a managed Kubernetes cluster helps us to reduce the complexities and overhead associated with managing the underlying infrastructure. Given a Docker container and a configuration file, Kubernetes manages all the deployment and networking automatically.
To streamline and standardize our deployments, we utilize “Helm charts” that define all the necessary components and configurations for our applications as code. Using infrastructure-as-code allows us to easily replicate our setup across different environments, as well as track changes, collaborate with team members, and maintain consistency throughout our development and production environments.
We open source our Helm charts in this GitHub repo and you can also add our Helm repo directly to your Helm CLI tool from the URL https://helm.polarlabs.ca.
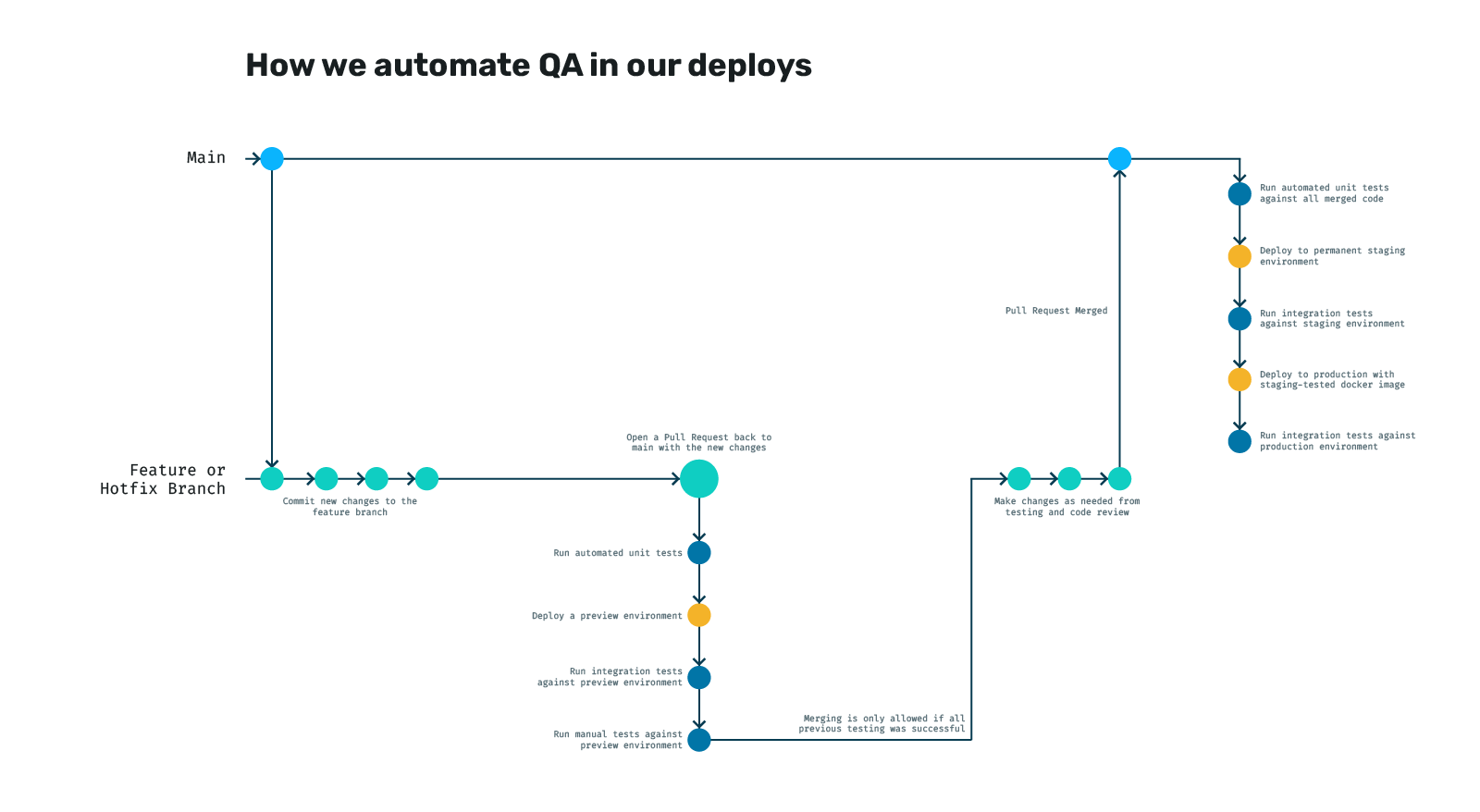
In practise, our deployments look something like this:
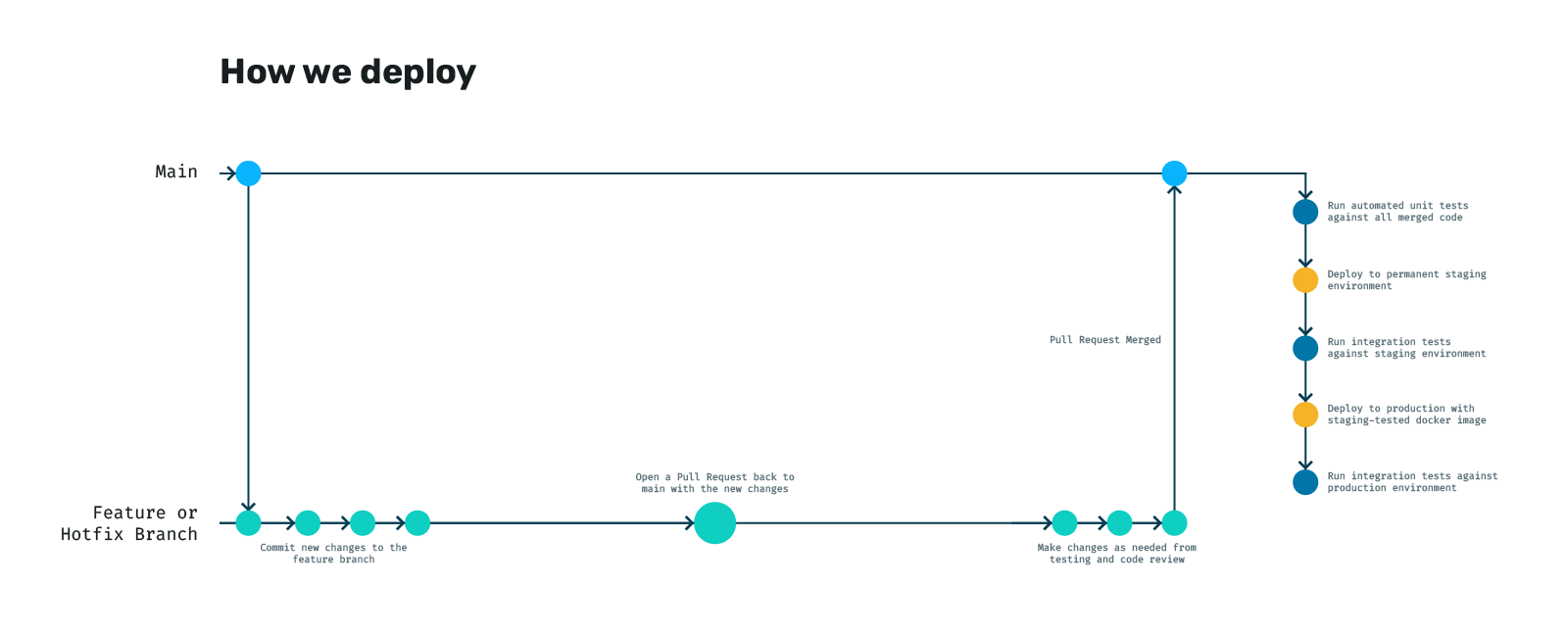
The idea is that every time we merge back to main, we automatically run a series of tasks that do their best to ensure nothing is broken by the time it makes it to production. In order, we do the following:
- Run all our units tests against the newly merged code in case there was a conflict or something overwritten that caused a regression (broke something that wasn't broke before)
- Build our Docker image and ship it to our private registry
- Deploy that docker to a permanent staging environment using our Helm charts
- Run our integration tests against that environment
- If they pass, we take the same image we just tested and use the same Helm charts with different plug-n-play variables to ship it to production
- Finally, as a smoke test, we run the integration tests one more time against production
This entire process is automated, and something we maintain in our StarterKits.
How we ensure quality and prevent regression
Maintaining quality while rapidly iterating on new features and fixes is a balancing act. Our approach heavily emphasizes testing throughout every stage of the development process. Every pull request triggers automated tests to catch potential issues early before they are merged into the main codebase. Additionally, each deployment – whether to a preview environment or production – undergoes automated testing to ensure that new code functions as expected and doesn't introduce regressions as described above.
Preview environments also play a crucial role in our quality assurance process. These temporary, isolated environments allow us to thoroughly test new code in a production-like setting without impacting the main staging or production environments. This not only saves valuable time by providing a realistic testing ground for new code, it also saves money because the preview environments only exist as long as we need them to, as compared to maintaining several long-running staging environments to test different things. By combining automated testing with preview environments, we confidently deliver high-quality software while maintaining a rapid development pace.
Adding to our diagram from before, here is what our pull request process looks like:
How we get new projects off the ground quickly
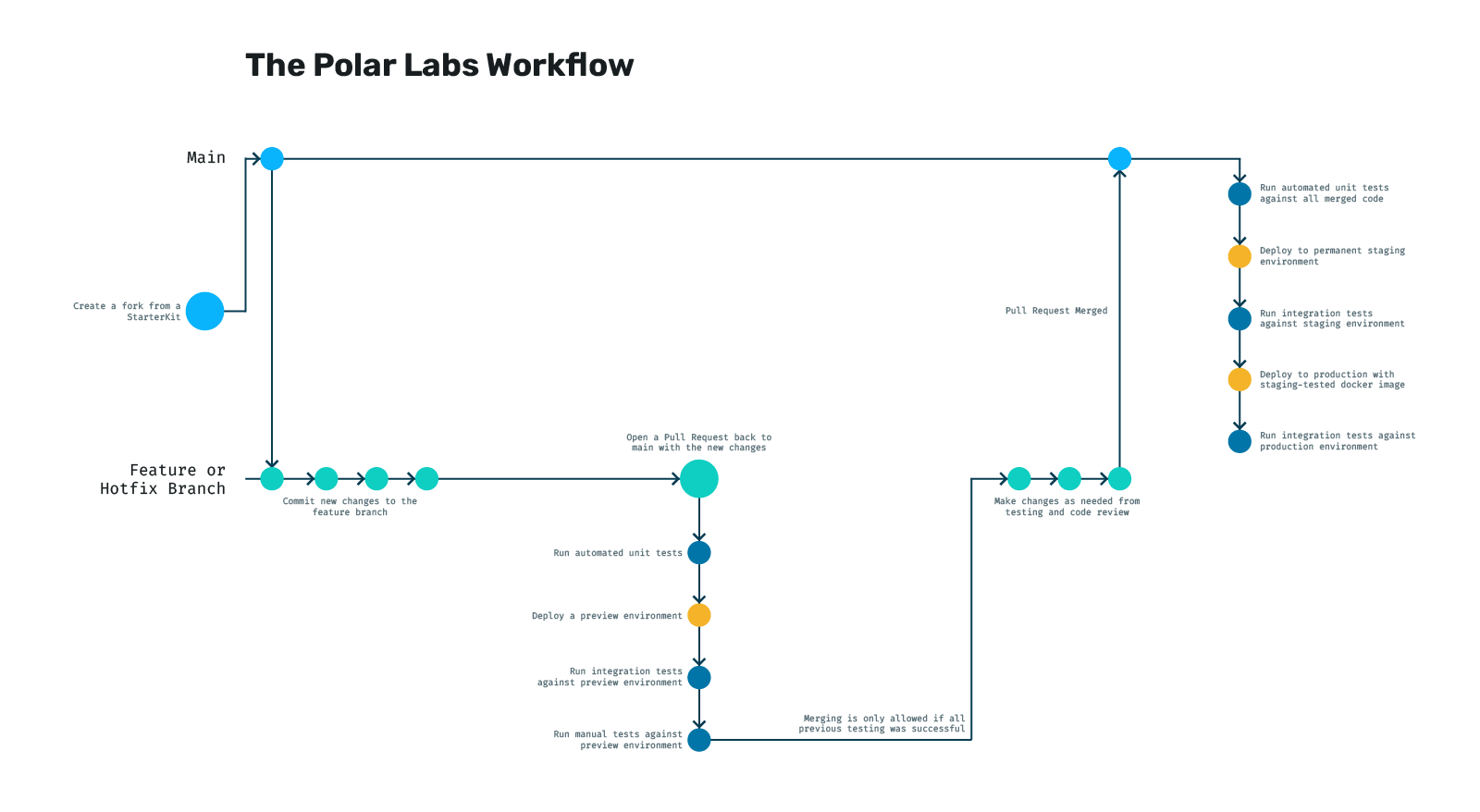
To expedite the setup of new projects, we maintain open-source StarterKits. These kits come equipped with pre-configured CI/CD pipeline files which provide the flows above out-of-the-box. They also come with Dockerfiles and the necessary code for a given framework to build and run with minimal configuration. When starting a new project, we simply fork a StarterKit with the technology that we intend to use, and then we start writing code. We package this deployment process into each of our StarterKits and use our own Helm repo to provide the deployment charts.
This approach allows us to focus on developing features rather than configuring complex deployment processes. It means that every time we start a new project, we can just think about the business logic of the application - not how we're going to get it online. It also means that any work we do for clients that originates from a StarterKit will continue to receive updates long into the future through what we continue to open source. You can read more about our StarterKits here.
Managing risk
We take a proactive approach that heavily emphasizes early testing to minimize bugs in our deployments with the following strategies:
- Automated testing: We rely on automated tests to catch regressions before they reach production. This gives us the confidence to deploy frequently without sacrificing stability.
- Multi-Layered testing: We test at multiple stages, including pull requests, merges, and deployments to staging and production environments.
- Preview environments: By using preview environments, we can catch issues early on without disrupting other developers' work using a long-running staging environment.
- Feature flagging and A/B testing: We can gradually roll out new features to a subset of users to test them in the real world before making them available to everyone.
- Incremental planning: Large tasks are broken down into smaller, more manageable ones, and hidden behind feature flags until they are fully tested and ready.
Why choose our approach?
Our approach to software deployment is focused on speed, efficiency, and developer experience in mind. We automate our deployments, ensuring a swift and reliable process that minimizes risk and downtime. By leveraging ephemeral preview environments, we eliminate the need for multiple costly, long-running staging environments, saving you resources and streamlining the development cycle.
We prioritize developer productivity by automating testing and reducing manual interventions. This allows your team to focus on what they do best – building high-quality software. Our streamlined release process creates a smooth and efficient path from development to production.
Our container-based infrastructure is flexible and adaptable to a wide range of applications, from simple websites to complex APIs. This versatility ensures that your software can run seamlessly as complexity and scale increases. Additionally, our approach allows for easy migration to different cloud providers, providing you with flexibility and control over your infrastructure.
Ready to streamline your DevOps?
Intrigued by the concept of a streamlined CI/CD pipeline that empowers your team to test and deploy with confidence? Use the Calendly widget below to book a meeting with us. We'd love to discuss how we can tailor these strategies to your specific needs and unlock the full potential of your development workflow.



{kind=link}