
As the AI wave continues to reshape the technology landscape, companies are quickly discovering that AI implementation isn't simply a matter of flipping a switch. Even simple chatbots now process queries through multiple layers of prompts, and frequently battle hallucinations and obscure responses. There is also a rightful spotlight on content and data, with an understanding that the output quality of your AI systems mimic the quality of your underlying data. Knowing that the needs of our clients will shift significantly towards the support and creation of these new AI systems, Polar Labs has been closely following and trying to challenge the latest best practices of AI implementation.
Researching is one thing, but to truly place ourselves in the AI space we knew we needed to get our hands keyboards dirty. This prompted us to explore what an ideal AI integration system might like by building our own Retrieval-Augmented Generation (RAG) system. Coming from a software engineering background, we approached this challenge with healthy skepticism about relying on tightly coupled AI and vector databases for accurate query responses.
Our approach was grounded in fundamental software engineering principles, particularly the concepts of interfaces and information hiding - which is the idea that when two systems interact, each party should need to communicate only the necessary information to complete a task, and the actual implementation of the task is hidden from each other. This architectural philosophy offers several advantages:
- Decoupling through interfaces: It prioritizes clear separation of concerns and information hiding between system components. This means the AI model interacts with data sources through well-defined APIs, without needing to understand their internal workings.
- AI as a front end: It views AI as another frontend interface, similar to a traditional UI, that can operate without requiring knowledge of the internal workings of the backend layer. This means the AI's scope is focused on understanding the user's intent (and generating the necessary params) and summarizing/formatting the information it received from the backend.
- Flexibility and scalability: It promotes flexibility and future proofing. Our interface-based approach allows changes to the data storage, retrieval methods, or even the type of database without impacting the AI frontend, as long as the API contract remains consistent between both systems. It also opens the door to patterns like Strangler Fig should we need to change the entire system.
By sharing our experience and findings in this case study, we aim to test our theories around how we can leverage these principles to build a more accurate and maintainable RAG system. Furthermore, we believe this approach can serve as a valuable starting point for organizations seeking to effectively leverage AI while maintaining a focus on common software engineering practices.
Hypothesis
Our understanding of traditional RAG systems leads us to believe there is a heavy reliance on vector stores and semantic search. While powerful, this approach presents limitations. We observed that these systems often struggle with hallucination, sometimes failing to retrieve the most contextually relevant information, particularly when dealing with outdated or conflicting sources. Moreover, relying solely on user-generated queries for accurate retrieval can be problematic, as end users often fail to articulate their needs effectively. Finally, tight coupling between the AI and the data retrieval mechanism can lead to significant rework when changes are needed in the underlying data infrastructure.
To address these challenges, we formulated a hypothesis centered on decoupling and abstraction. Instead of relying on semantic search and coupling the AI to the complexities of the data retrieval process, we propose the following enhancements to the overall system:
-
Hiding the logic of information retrieval behind an interface. This would involve creating a simple API to handle the intricacies of data search, leaving the AI free to focus on higher-level tasks.
-
Tasking the AI with determining the API parameters. This would enable the AI to refine the user's query and translate it into a structured request that aligns with the API contract. We are no longer relying on it to be able to determine the most relevant data itself - we would just ask it to read the results the API provides it.
-
Preprocessing our data chunks with AI. This would enrich the chunks with metadata and rewrite them using AI to be more structured and consistent. The metadata would allow for more efficient and accurate retrieval by enabling pre-filtering of results before sorting by semantic similarity of just the relevant chunks.
-
Reducing hallucinations by treating the AI as a front end. By limiting the AI's role to generating API parameters and interpreting the results, we aim to minimize the risk of the AI generating unsupported or incorrect information.
By implementing these strategies, we theorized we could create a more robust and reliable RAG system that effectively leverages the strengths of AI while mitigating its perceived weaknesses.
Materials
- ~120 car brochures downloaded from Auto-Brochures
- We began by following this tutorial on Snowflake: Build A Document Search Assistant using Vector Embeddings in Cortex AI
- As a Snowflake Select partner, we have access to our own demo account to perform these sorts of experiments. The tools we used were:
- Cortex
- SQL-based UDTFs
- Streamlit
- Document AI
- Tables containing vectored columns
- Python Snowpark using libraries like PyPDF2 for text extraction
- Internal Stages
- Gemini and Claude for assistance in prompt engineering (and assistance writing this case study!)
Method
To assess the validity of our hypothesis and evaluate the impact of our improvements, we conducted a comparative analysis between a "traditional" RAG setup and our modified system. We began by following the Snowflake tutorial to implement a baseline system, with minor adjustments such as incorporating Document AI for enhanced data processing. This initial setup relied solely on the vector store for retrieving relevant chunks and displaying the results in a Streamlit app.
Next, we cloned the resources and refactored the code to incorporate more robust prompt engineering techniques and abstracted the search functionality into a SQL User-Defined Table Function (UDTF). The UDTF accepted parameters such as manufacturer, model, and year, enabling more targeted data retrieval.
Finally, we created a second chunk table (very originally named better_chunks_table) preprocessed with AI, to generate richer and more informative chunks. Both the baseline system and our modified system were then connected to better_chunks_table to compare their performance in responding to user queries.
1. Selecting our data source
Our choice of data source was guided by several key criteria. We sought data that was readily available, was reasonably standardized, and could be easily understood and utilized by a broad audience. We also wanted the data in document format (instead of tabular) to explore different chunking and data extraction techniques. Finally, the data needed to include distinct "versions" to evaluate the system's ability to retrieve information from the correct source.
After much internal deliberation and passionate soapboxes, we settled on car specification data that we could extract from PDF sales brochures spanning multiple years. This data allowed us to create a variety of test queries, such as those related to feature availability, fuel economy comparisons, and model-specific information, and most importantly have this span different years.
2. Extracting and Preparing the Data
Following the Snowflake tutorial, we utilized the PyPDF2 Python library to extract text from the PDF brochures. This extracted text was then chunked into segments of 4000 characters, mirroring the tutorial's settings. These chunks were stored in a table named chunk_table, which included a vectorized column called chunk_vec to facilitate semantic search.
We then experimented with Snowflake's Document AI to enrich the chunks in our table with metadata. We trained a Document AI model to extract the manufacturer, model, and year from the brochures, as we felt that these three dimensions would be available for all cars. Achieving an acceptable confidence level of 80+% required training the model on approximately 80 documents.
After the model was trained, we processed each document through Document AI and tagged each corresponding chunk in chunk_table with the extracted metadata. This allowed us to utilize standard SQL queries for filtering based on these attributes. Unfortunately, this method of metadata generation proved to be both unreliable and costly, as we will further elaborate in the Results section.
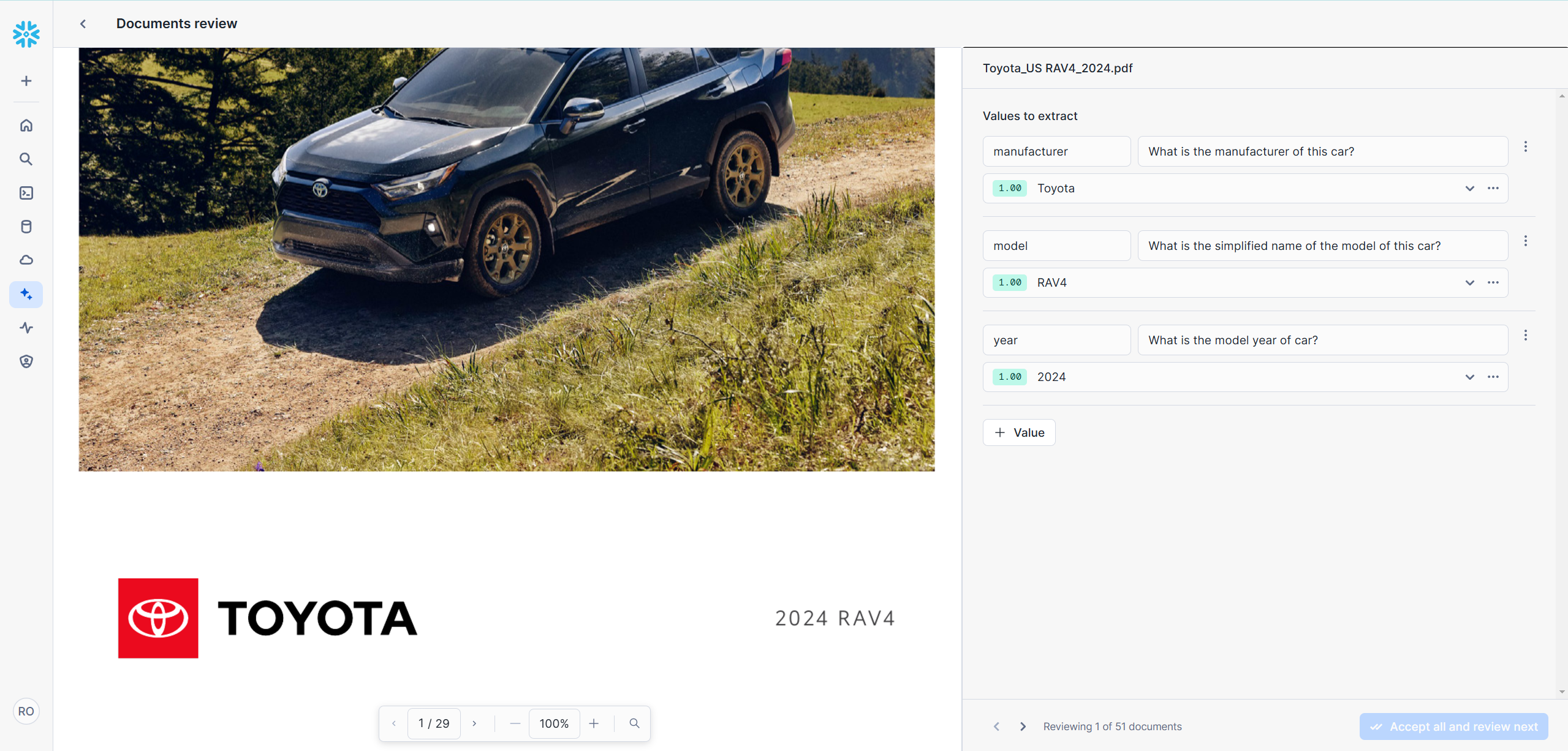
3. Building the first Streamlit App
Following the Snowflake tutorial, we developed our baseline system using Streamlit. The implementation centered around a create_prompt method that directly accessed SNOWFLAKE.CORTEX.COMPLETE without a system prompt, using vector similarity-based retrieval through basic SELECT queries ordered by VECTOR_COSINE_SIMILARITY.
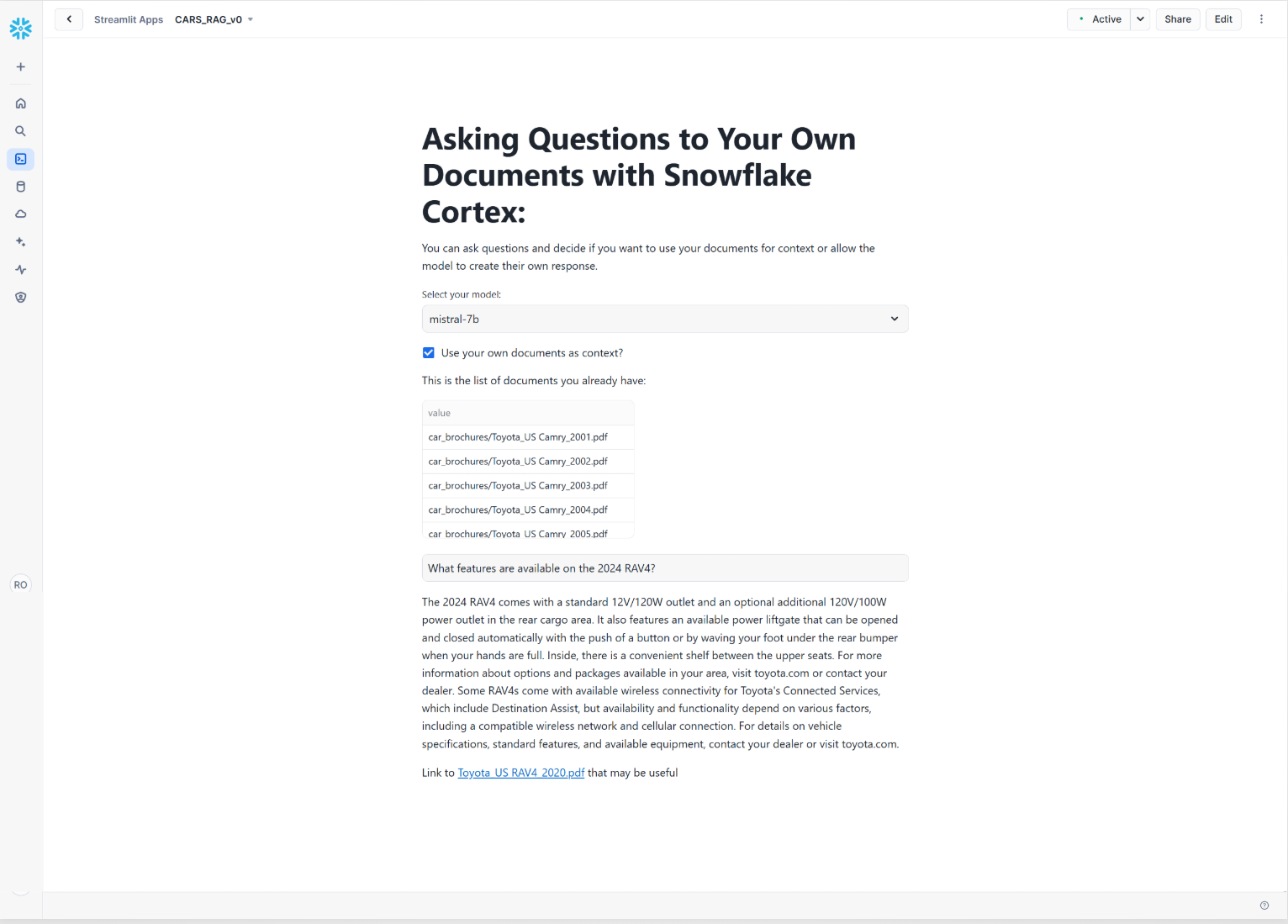
This baseline implementation demonstrated fundamental RAG capabilities but the system frequently retrieved information from incorrect brochures, omitted relevant details, or provided inaccurate answers.
This issue is illustrated in the screenshot below, where the system confidently answers a question about the 2024 Toyota RAV4 while referencing the 2020 brochure:
4. Improving the prompts
To enhance the accuracy and relevance of the AI's responses, we modified the SNOWFLAKE.CORTEX.COMPLETE command to accept a system prompt in addition to the user prompt. This system prompt provided instructions and context to guide the AI's response generation. We continued to inject the results of the document query as context before the user query.
With the help of Gemini and Claude, we iteratively refined the system prompt to look like this:
You are an expert assistant summarizing automotive information from car brochure excerpts. Your responses should:
1. Context Usage:
- Prioritize information from the provided context
- Cite specific trims/variants when relevant
- Note when information varies by region/market
- Indicate if context appears outdated
- Acknowledge conflicting information if present
2. Response Format:
- Use markdown formatting
- Structure responses with clear headings for multiple features
- Include units in standard formats
- Keep responses concise
- Highlight confidence level when relevant
3. Information Gaps:
- Clearly state when information is not found in context
- Ask for clarification if trim level/year/variant is needed
- Indicate when related important information is missing
- Do not speculate or fill in gaps with general knowledge
- If the question does not specify a year, assume the latest available
4. Technical Details:
- Prioritize specific measurements and specifications
- Note when features are standard vs. optional
- Distinguish between objective specifications and marketing claims
- Include relevant compatibility or requirement information
When answering, be direct and concise to the question asked while ensuring accuracy. Don't pad with unecessary information.
If the user's question cannot be fully answered from the context, explain what additional information would be helpful.
Furthermore, we introduced an intermediary step to leverage AI for query refinement. This involved extracting relevant metadata from the user's query, which would be used in the subsequent step to further refine the search. This process was guided by another system prompt that incorporated few-shot prompting to help the AI understand our requirements:
You are a consistent assistant whose job is to take a user query about car features and refine it to a more
specific question suitable for searching car brochures. You must also extract the manufacturer, model name,
and model year from the query. There might be multiple possible answers for each field, follow the instructions carefully.
To do this:
1. Extract vehicle information:
- manufacturer (required)
- model_name (required)
- model_year (required, convert partial years to full YYYY format, it must be a number anything other than a number is invalid)
2. Refine the query:
- Use technical terminology found in brochures
- Focus on specifications and features
- Be concise and specific
- Maximum length: 300 characters
- Include standard units (MPG, cu.ft, hp, etc.)
- Preserve multiple related specifications if present
3. Return a JSON object with these fields:
{
"manufacturer": string,
"model_name": string,
"model_year": string,
"refined_query": string
}
If required fields are not present in the input, set them to null.
If you detect multiple possible answers for a field separate them with commas without spaces.
Example input: "Is the Toyota corolla good on gas?"
Example output:
{
"manufacturer": "Toyota",
"model_name": "Corolla",
"model_year": null,
"refined_query": "Fuel economy figures for the Toyota Corolla, including city, highway, and combined MPG."
}
Example input: "Compare the prius and corolla fuel efficiency"
Example output:
{
"manufacturer": null,
"model_name": 'Prius,Corolla',
"model_year": null,
"refined_query": "Toyota Prius Toyota Corolla fuel economy MPG comparison highway city combined fuel efficiency specifications"
}
Example input: "Compare the base features of corolla 2020 and 2022 and tell me what's new"
Example output:
{
"manufacturer": null,
"model_name": 'Corolla',
"model_year": '2020,2022',
"refined_query": "Toyota Corolla 2020 2022 standard features base model specifications comparison changes updates differences model year improvements"
}
While these modifications increased the prompt length and token consumption, they significantly improved the quality of the results. We felt this trade-off was worthwhile, particularly in the context of a proof-of-concept. However, we acknowledge that there is plenty of room for optimization and refinement in a production-ready version.
5. Extracting the search to the UDTF
Following our hypothesis about interface-based design, we modularized the search functionality by creating a User-Defined Table Function (UDTF) named GET_RELEVANT_CAR_CHUNKS. This UDTF served as a proxy for an API in this proof-of-concept, providing a well-defined interface for data retrieval. In a production environment, a dedicated API would likely offer greater flexibility and the ability to source data from multiple locations such as an external API.
The GET_RELEVANT_CAR_CHUNKS function performs the following key tasks:
-
Accepts a search query and optional filters: The optional filters are
manufacturer,model, andyear. These filters enable pre-filtering of results before applying semantic similarity ranking. - Utilizes vector embeddings for ranking: It leverages vector embeddings to sort the results based on semantic similarity to the provided search query.
- Returns relevant chunks with metadata: It returns up to 20 of the most relevant text chunks, along with associated metadata and source file URLs.
-
Handles multiple filter values: The filters can accommodate multiple comma-separated values (e.g., "COROLLA,PRIUS" for the
modelfilter). - Prioritizes newer results: It only returns matches with at least 25% similarity and prioritizes chunks from newer brochures when similarity scores are equal (after rounding).
-- Apparently you can't use variables to put a limit on a query
-- so for now I am hardcoding the limit since this is just a POC
-- but we would need something more dynamic in a production setting
-- for now limit dynamically in python
CREATE OR REPLACE FUNCTION GET_RELEVANT_CAR_CHUNKS(
SEARCH_TEXT VARCHAR,
MANUFACTURER_NAME VARCHAR DEFAULT NULL,
MODEL_NAME VARCHAR DEFAULT NULL,
YEAR_Q VARCHAR DEFAULT NULL
)
RETURNS TABLE(
CHUNK VARCHAR,
FILE_URL VARCHAR,
FILE_NAME VARCHAR,
LAST_MODIFIED TIMESTAMP_TZ(3),
MANUFACTURER VARCHAR,
MODEL VARCHAR,
YEAR VARCHAR,
SIMILARITY FLOAT
)
LANGUAGE SQL
AS
$$
SELECT
REFINED_CHUNK_W_METADATA as CHUNK,
GET_PRESIGNED_URL(@car_brochures, FILE_NAME) as FILE_URL,
FILE_NAME,
LAST_MODIFIED,
INITCAP(MANUFACTURER) AS MANUFACTURER,
INITCAP(MODEL) AS MODEL,
YEAR,
ROUND(VECTOR_COSINE_SIMILARITY(
CHUNK_VEC,
SNOWFLAKE.CORTEX.EMBED_TEXT_768('snowflake-arctic-embed-m-v1.5', SEARCH_TEXT)
), 2) AS SIMILARITY
FROM
BETTER_CHUNKS_TABLE
WHERE
-- This is a little hacky but works for POC purposes
(MANUFACTURER_NAME IS NULL OR MANUFACTURER IN (SELECT s.value FROM TABLE (SPLIT_TO_TABLE(REGEXP_REPLACE(UPPER(MANUFACTURER_NAME), '\\s+', ''), ',')) AS s))
AND (MODEL_NAME IS NULL OR MODEL IN (SELECT s.value FROM TABLE (SPLIT_TO_TABLE(REGEXP_REPLACE(UPPER(MODEL_NAME), '\\s+', ''), ',')) AS s))
AND (YEAR_Q IS NULL OR YEAR IN (SELECT s.value FROM TABLE (SPLIT_TO_TABLE(REGEXP_REPLACE(UPPER(YEAR_Q), '\\s+', ''), ',')) AS s))
AND SIMILARITY > 0.25
-- show newer models first when unspecified
ORDER BY SIMILARITY DESC, YEAR DESC
LIMIT 20
$$;
6. Enhancing Data Quality and Chunking Strategy
Our initial data extraction process yielded chunks that contained a significant amount of marketing jargon and extraneous information. Furthermore, the original chunk size of 4000 characters proved to be excessively large, consuming a considerable number of tokens without a corresponding improvement in response quality (possibly the opposite in fact).
To address these issues, we implemented the following refinements:
- Reduced chunk size: We decreased the chunk size to 100 words, striking a better balance between context and token consumption, and making sure chunks aren't cut off mid word by counting characters instead of words.
- AI-powered data refinement: We employed an AI model to process the extracted text, removing marketing fluff and retaining only factual information. This process also involved structuring the data with headings and metadata for improved organization and searchability.
- Feature extraction: In the system prompt for the AI preprocessing, we explicitly instructed the model to extract relevant features and preserve units of measurement. This ensured that the resulting chunks were more concise, informative, and conducive to accurate retrieval.
SNOWFLAKE.CORTEX.COMPLETE(
'mixtral-8x7b',
'
You are a car specification expert. Rewrite the following car brochure text to be clear, structured, and searchable.
Follow these rules:
1. Keep all specific numbers, measurements, and technical specifications
2. Convert marketing language into factual statements
3. Structure information in a consistent format
4. Explicitly state the feature name and its benefit
5. Use standard automotive terminology
6. Preserve all model-specific details
7. Format lists of features clearly
8. Be concise
' || chunk || '
Rewrite this as clear, searchable text following the rules above.
Do not respond as if this is a chat. Only provide the formatted information to be saved in a database.
'
)
These enhancements significantly improved the quality of our data chunks, resulting in more focused information and a more efficient use of tokens. This, in turn, contributed to more accurate and relevant responses from the AI system. What this looks like can be seen below in the following screenshots:
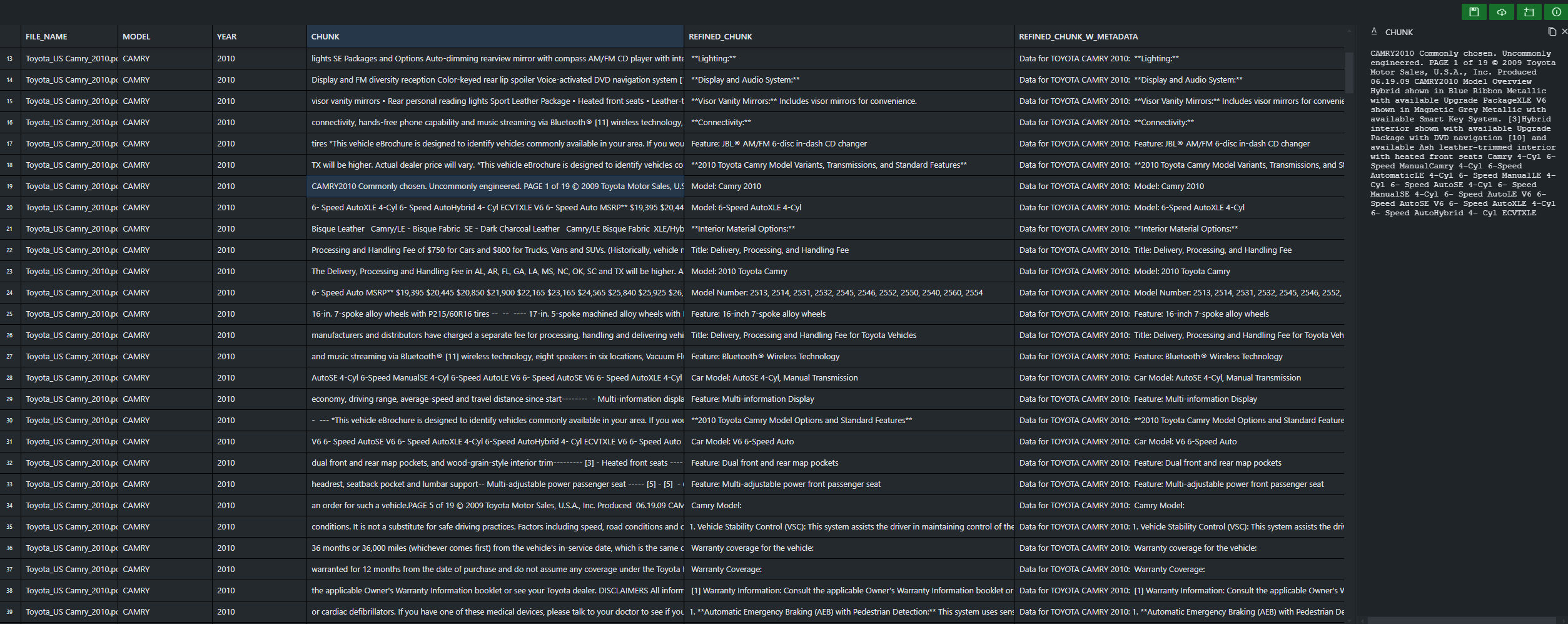
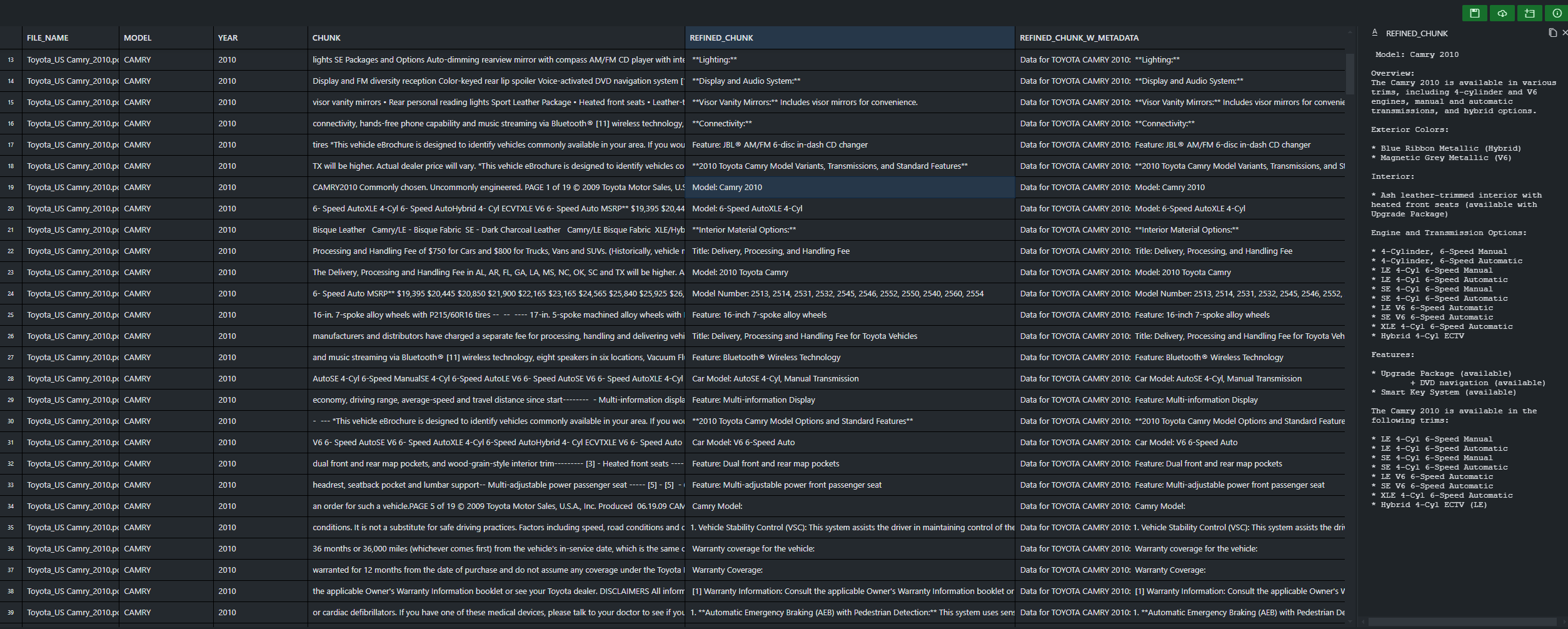
Finally, we incorporated the extracted metadata directly into each chunk before vectorization. This contextual enrichment aimed to improve the AI's ability to differentiate between documents and reduce instances of mixing information from different sources, especially when responding to year-specific queries.
This refined data, along with its enriched metadata, was stored in a new table named better_chunks_table. This improved dataset formed the basis for further evaluation and comparison with the initial chunk_table.
7. Hooking it all up
To evaluate the effectiveness of our refined approach, we developed a second Streamlit application. This application included a debug mode, providing transparency into each step of the process and facilitating analysis.
The final workflow incorporates the following steps:
-
Preprocessing:
better_chunks_table, containing preprocessed and enriched data chunks, is prepared beforehand. - User Input: The user enters a query in the Streamlit application.
-
Query Refinement: The "refiner" step utilizes
snowflake-arcticto generate a JSON object containing extracted values formanufacturer,model, andyear, along with a refined and elaborated version of the user's query optimized for semantic search. We foundsnowflake-arcticto be most consistent at generating valid JSON. -
Data Retrieval: The
GET_RELEVANT_CAR_CHUNKSUDTF is invoked. This function executes a SQL query that pre-filters the chunks based on the extractedmanufacturer,model, andyearbefore sorting them by semantic similarity. A minimum confidence level is enforced, and newer brochures are prioritized in the ranking making them most likely to be injected into the final prompt. - Response Generation: The retrieved results are fed into a final query along with a system prompt. This prompt instructs the AI to generate a concise, Markdown-formatted response and explicitly state when it cannot find the answer within the provided context.
This integrated system, with its refined data, enhanced prompts, and decoupled search functionality, represents our proposed approach to building a more robust and reliable RAG system. The following sections will delve into the results of our evaluation and discuss the key findings and insights.
Results
Our refined RAG system demonstrated a substantial improvement in both the quality and accuracy of responses compared to the initial implementation. While our proof-of-concept version revealed some limitations (discussed in the next section), the overall results were highly encouraging.
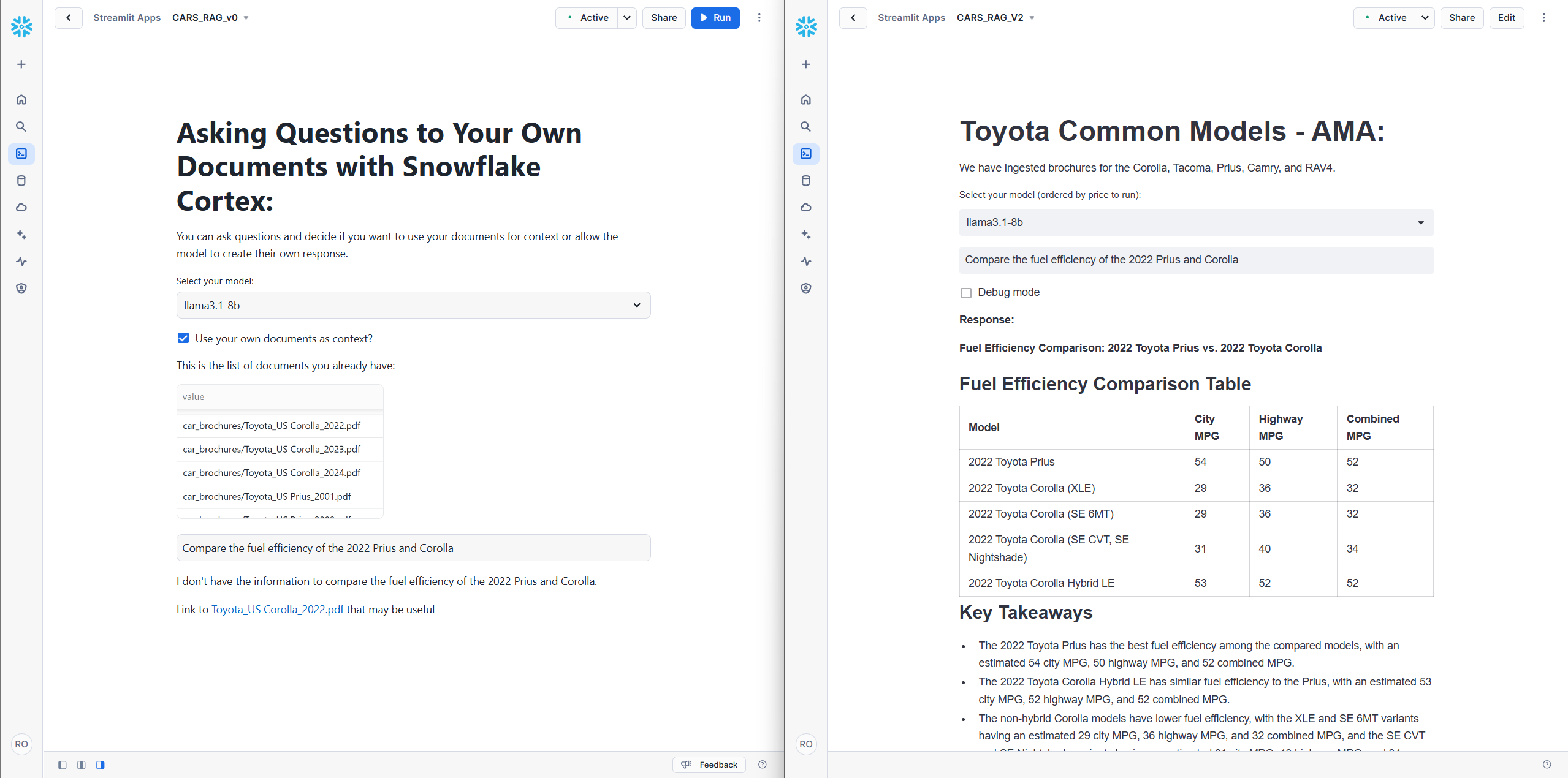
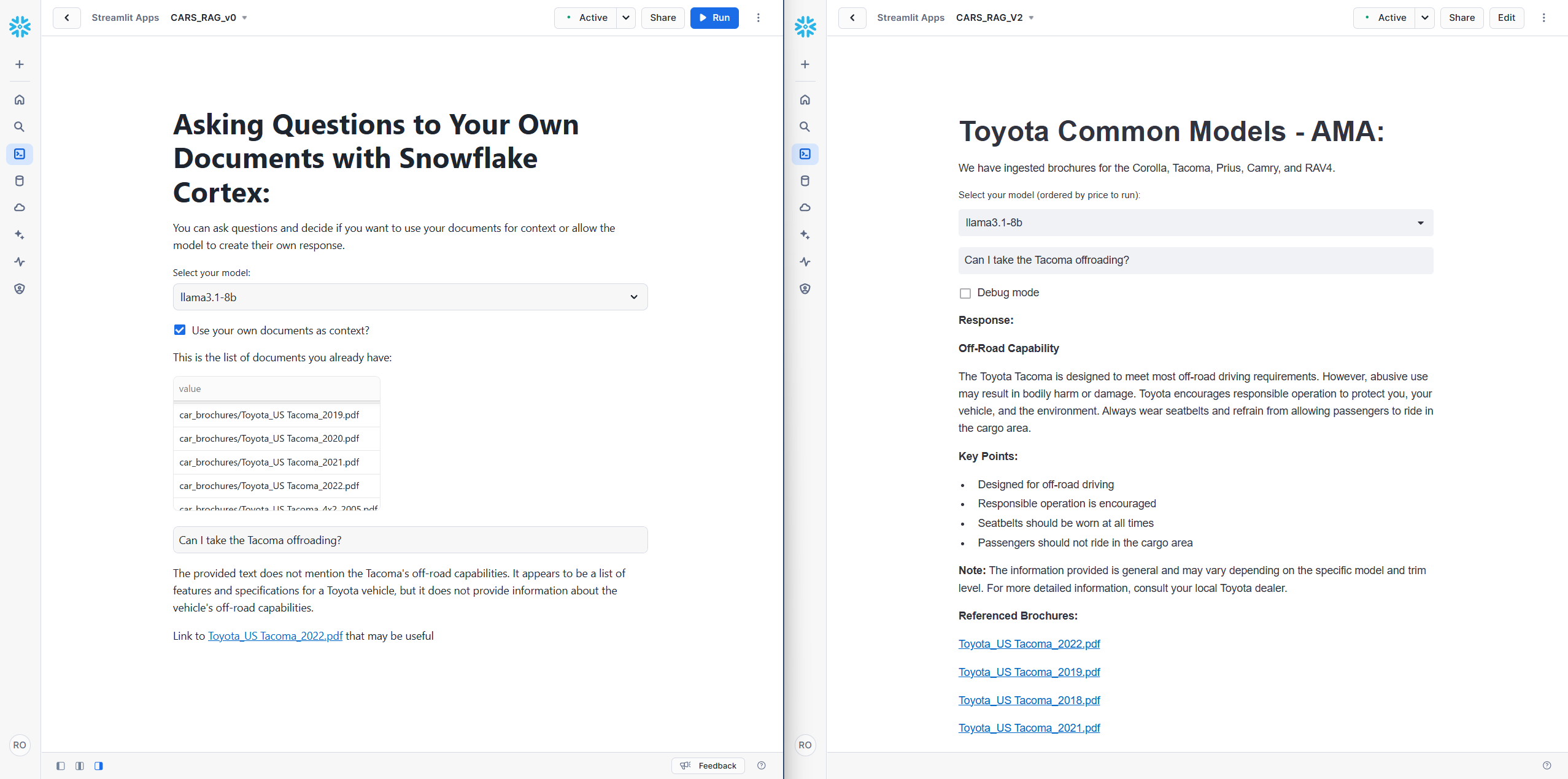
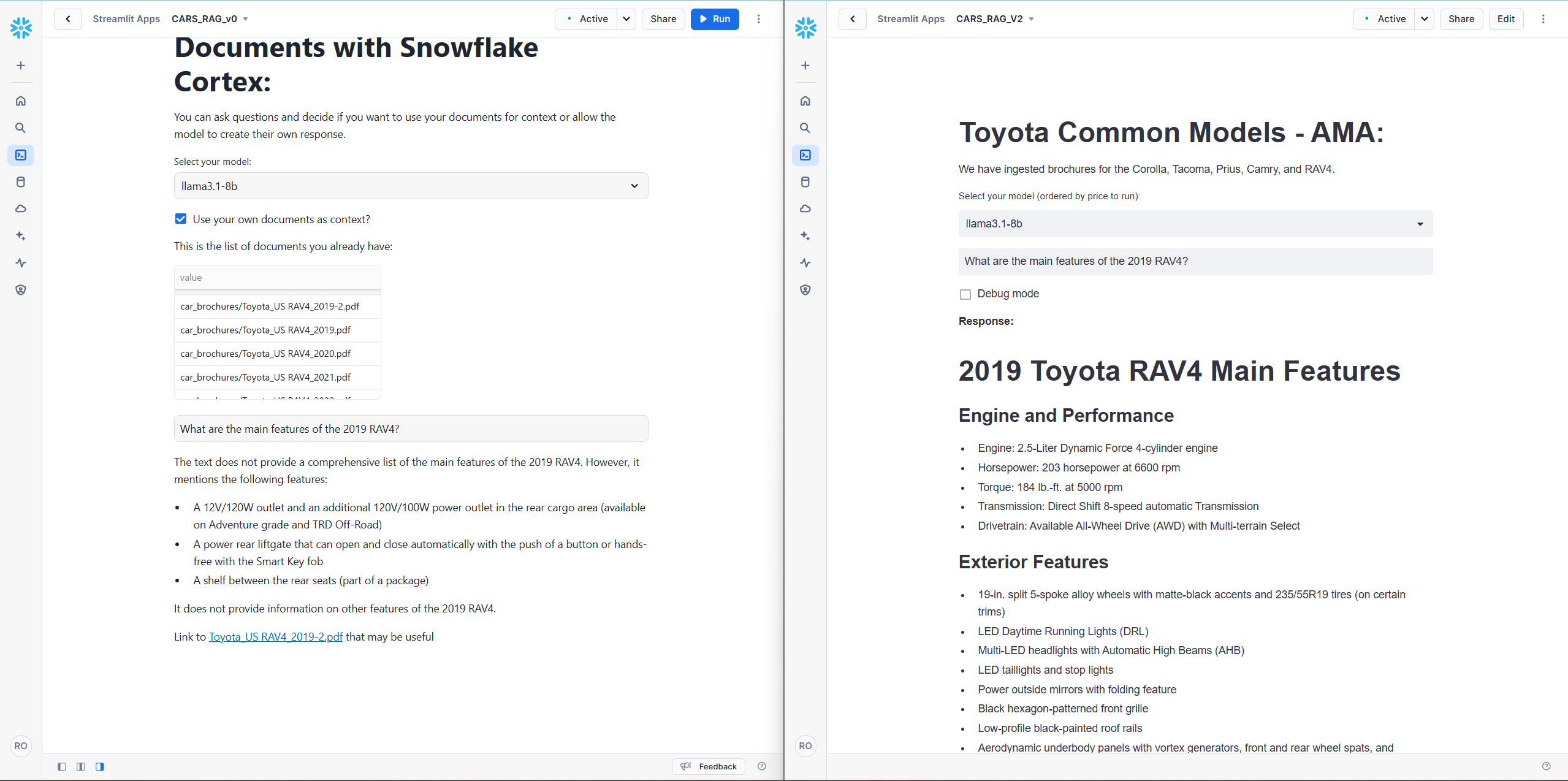
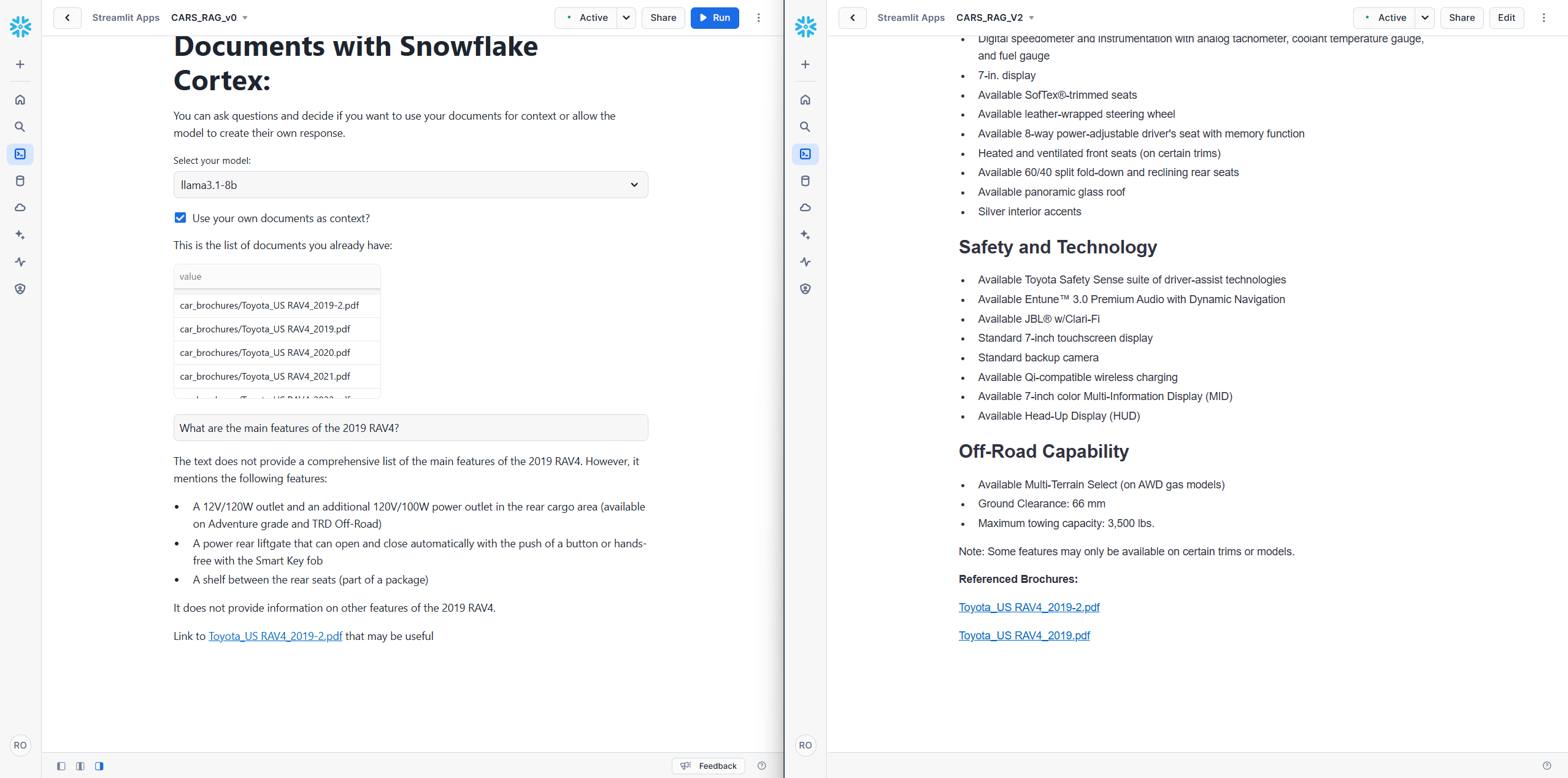
- Improved Data Source Accuracy: By pre-filtering brochures before applying semantic sorting, our RAG system consistently retrieved information from the correct source. This addressed a key challenge observed in the initial implementation, where irrelevant or outdated sources were often referenced.
- Enhanced Response Quality: Pre-filtering ensured that the limited token space within the prompt was dedicated to relevant chunks from the correct document. This richer context allowed the AI to generate more accurate and comprehensive answers.
- Impact of System Prompts: The inclusion of a refined system prompt significantly improved the quality of responses. Insisting on Markdown formatting enabled the AI to generate structured outputs, including tables. However, we observed a tendency to overcorrect for hallucination, with the AI sometimes refusing to answer questions unless it had access to the exact information required.
-
Simplified Maintenance: Our modular design, with the search logic abstracted into a UDTF, significantly simplified maintenance. We noticed this even within the context of the POC when we switched to the
better_chunks_tablewithout having to modify the Streamlit application code at all. Similarly, initially we built the system to only answer questions about one car at a time, but we easily adapted the UDTF to handle multiple car queries and only had to change the system prompt to separate multiple answers with a comma. - Effective AI Preprocessing: Preprocessing both user queries and data chunks with AI led to noticeable improvements. The AI effectively translated user queries into more precise representations that better aligned with the preprocessed chunks, resulting in more accurate and relevant responses.
To illustrate these improvements, we present a series of side-by-side comparisons between the original Snowflake tutorial version and our refined system. For fairness, both versions utilize the better_chunks_table, allowing them to benefit from the enhanced data quality.
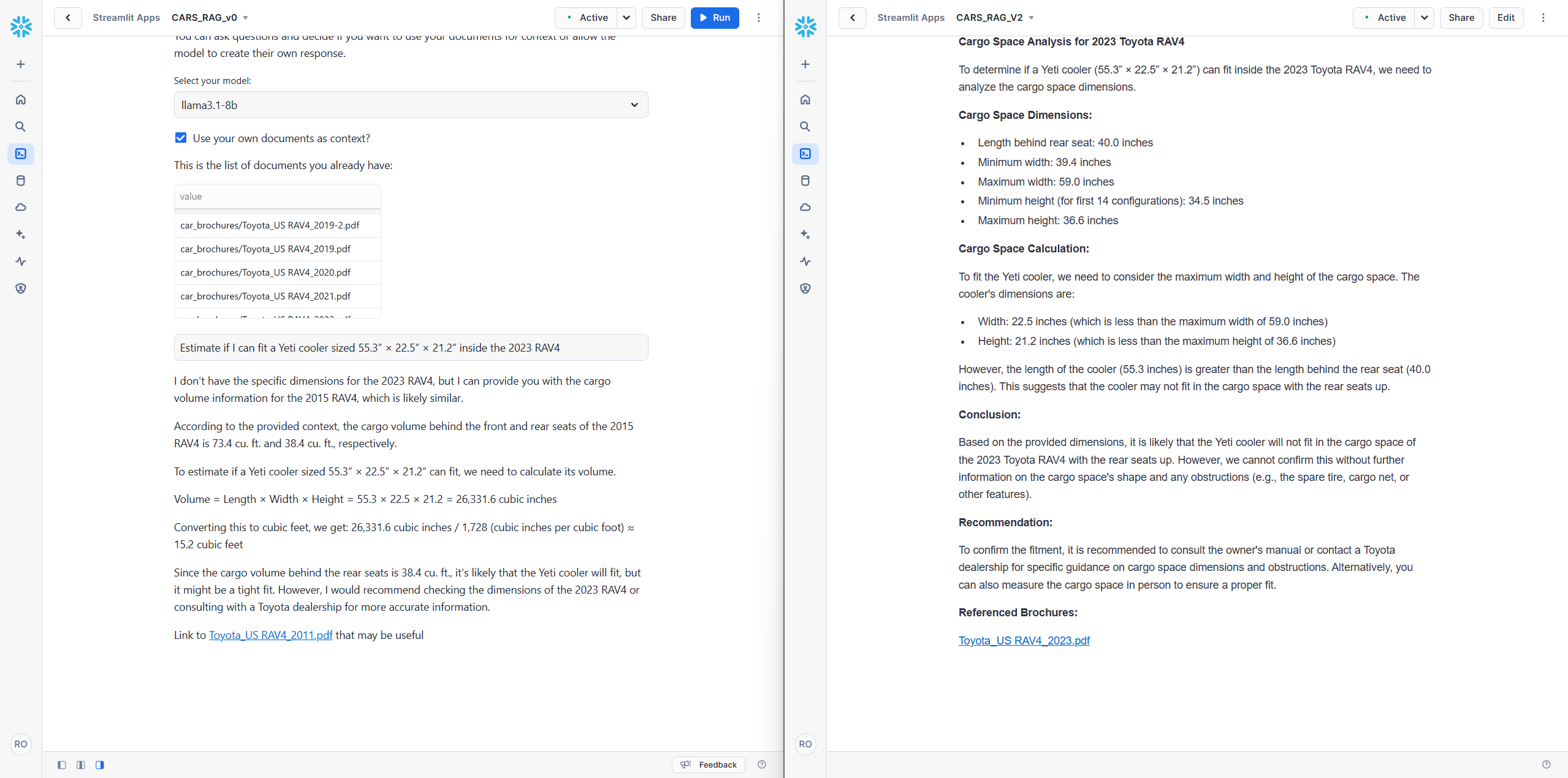
Limitations
While we are pleased with the overall performance of our refined RAG system, our proof-of-concept implementation revealed several limitations and areas for improvement:
- Handling complex prompts: The system struggles with certain types of prompts, particularly those involving comparisons across multiple models but with vague parameters. For example, a query like "compare the Prius to all other models" can lead to the system to solely on Prius brochures, even though our approach excels at handling specific comparisons like "compare the Prius and the Corolla from 2020 and 2022". This limitation could potentially be addressed through improvements to the query refinement process or by fine-tuning the refiner model to better handle these edge cases.
- Generating JSON consistently: We found that while
snowflake-arcticwas very consistent, sometimes it would still fail to generate valid JSON and break our streamlit app unexpectedly. In a production-grade environment we would need a way to ensure valid JSON 100% of the time. - Constraints of SQL/UDFs: Directly using SQL and UDFs introduced challenges. For instance, the inability to dynamically set the
LIMITfield or passNULLvalues to parameters expectingVARCHARtypes required workarounds. Additionally, converting dataframe responses to simple strings for use in prompts seemed inefficient. We believe that a dedicated API would offer greater flexibility, including the ability to handle multiple data sources and potentially access external information/APIs when necessary. - Challenges with Document AI: Our experience with Document AI was less than satisfactory. It misidentified the car model or year about a quarter of the time, despite being trained on a significant portion of the dataset. We also encountered a bug where it failed to return any values for half of our documents in the initial run, necessitating a costly second execution. This resulted in approximately $280 cumulatively in charges while processing only ~120 multi-page documents (~60 the second time). This raises concerns for us about its scalability and cost effectiveness. The processing time, exceeding one hour for each batch run, further compounds these concerns. While Document AI holds promise, we feel its current limitations in terms of accuracy, cost, and speed hinder its practical applications, at least in the context we used it in.
- Overcorrection for hallucination: The system in its current form, tends to overcorrect for hallucination. While this generally improves accuracy, it can be difficult to get the AI to actually answer your question. For example, when asked if a Yeti cooler can fit in a Prius, the system refused to provide an answer unless it had the explicit dimensions of the cooler. It would also only answer the question if you asked it to guess, refusing a definitive answer. While we feel this is better than hallucinating, there is clearly more work to be done here for a production-ready version.
- Importance of high-quality data: This experience highlighted the critical importance of high-quality base data. As queries get more technical, the system struggles due to marketing content being light on details, or information being obfuscated in comparison tables that use checkmarks to denote which car has which feature. This was sufficient for our POC, but for a production-ready system we feel it would end up being necessary to spend far more time preparing and maintaining the underlying data than the RAG part of the system.
Conclusions
This case study explored our hypothesis that a RAG system that was built on principles of decoupling and abstraction can significantly improve the accuracy, maintainability, and response quality of AI-driven information retrieval. By abstracting search functionality, enriching data with AI, and refining prompts, we feel that we achieved notable improvements over a traditional approach reliant on semantic search and relying on the AI to parse the resulting information.
We observed promising results in terms of accurate source retrieval, hallucination mitigation, and ease of maintenance. However, it's important to acknowledge that this was a proof-of-concept, and further development would be needed to fully validate these findings. All in all, we spent about 10-15 hours collectively on this POC, and even in that short time frame our exploration revealed several areas for improvement.
Challenges with complex prompts, limitations of SQL/UDFs, and the need for more robust data enrichment techniques suggest avenues for future investigation. Balancing conciseness with the risk of hallucination also requires careful consideration and further experimentation.
Moving towards a production-grade system would likely involve the following tasks:
- Developing a dedicated API instead of a UDTF: To enhance flexibility and data source integrations.
- Refining the refiner model: To better handle complex comparisons and edge cases. We believe that a refiner model like we used would greatly benefit from fine-tuning.
- Exploring alternative data enrichment techniques than Document AI: For improved accuracy and cost-effectiveness. Furthermore, this would need to be built as a continuous pipeline - not a one-off batch process.
- Optimizing the balance between conciseness and hallucination: Through ongoing prompt engineering and model fine-tuning.
- Investing in high-quality data: As a foundation for accurate and comprehensive responses. Potentially including other sources through external APIs or tabular data.
- Building data ingestions pipelines: In our POC we simply downloaded a fixed number of brochues and processed them in batch. In a real system we would need to be able to continuously improve on and make available new data.
We believe our case study offers valuable insights into the potential benefits and challenges of an interface-based approach to RAG system design. We believe that further development and experimentation in this area can contribute to more robust and reliable AI-driven information retrieval systems.


